How to Optimise Token Efficiency
Effectively managing token usage is essential due to its direct impact on both cost and performance. Here’s what we’ve learned about token efficiency since launching V7 Go!
What are tokens, anyway?
In LLMs, tokens are the fundamental units of text processing that models use to interpret and generate human-like language. A token can represent a word, subword, punctuation mark, or even a single character. When an LLM processes text, it breaks down the input into tokens, converting them into numerical vectors that the model can interpret and analyze. During text generation, the model predicts subsequent tokens based on preceding context to create a coherent response.
Why is token efficiency important?
Token efficiency is crucial because it directly influences the cost and quality of your workflows in Go. Every additional token requires processing resources which increases computational costs. By refining token management, users can harness the full potential of Go and LLMs while minimizing expenses.
I’ve just started using V7 Go: how can I use my tokens most efficiently?
V7 Go empowers you to chain together multiple LLMs to solve tasks reliably, and at scale.
Based on our experience working with customers since launching in April 2024, here are some tips and tricks to optimize your token usage:
Tip 1: Consolidate Reference Data Before Processing
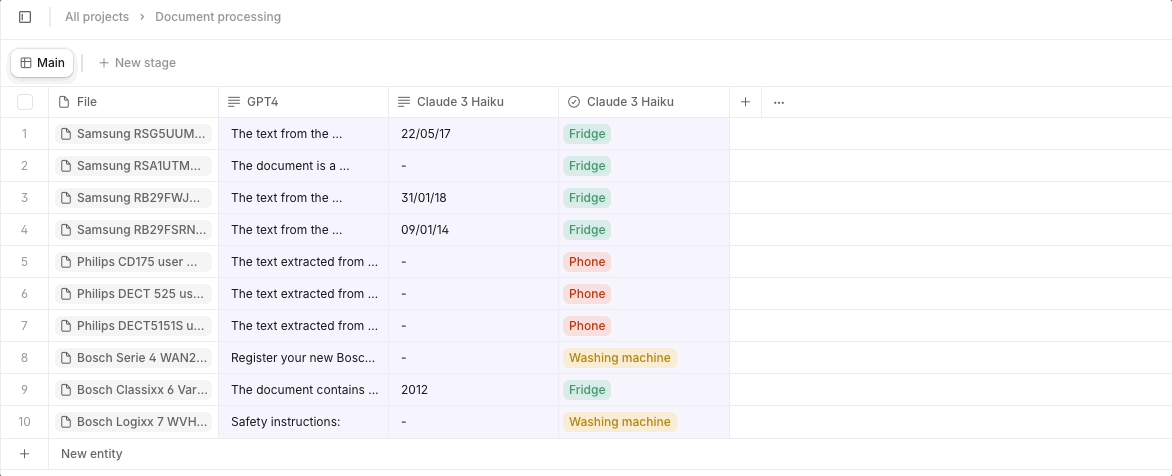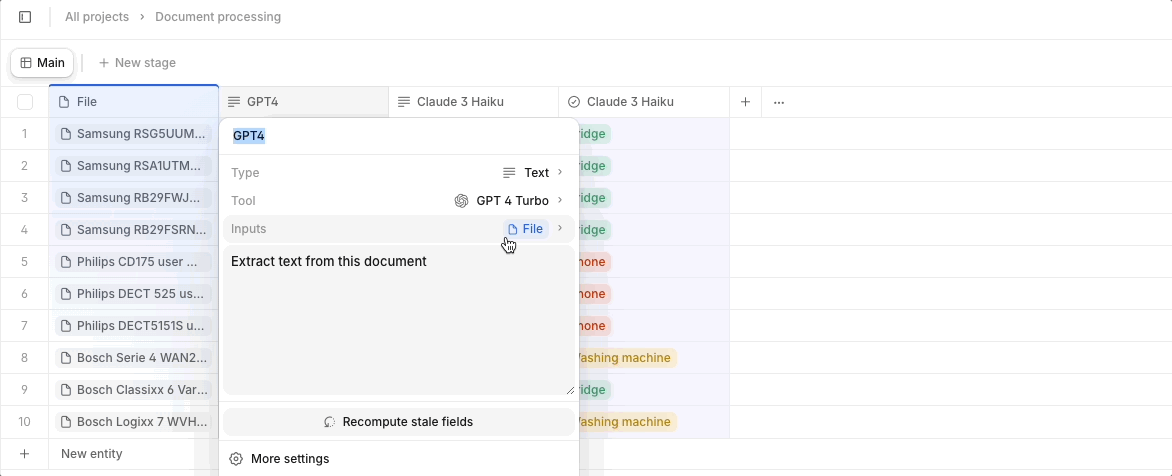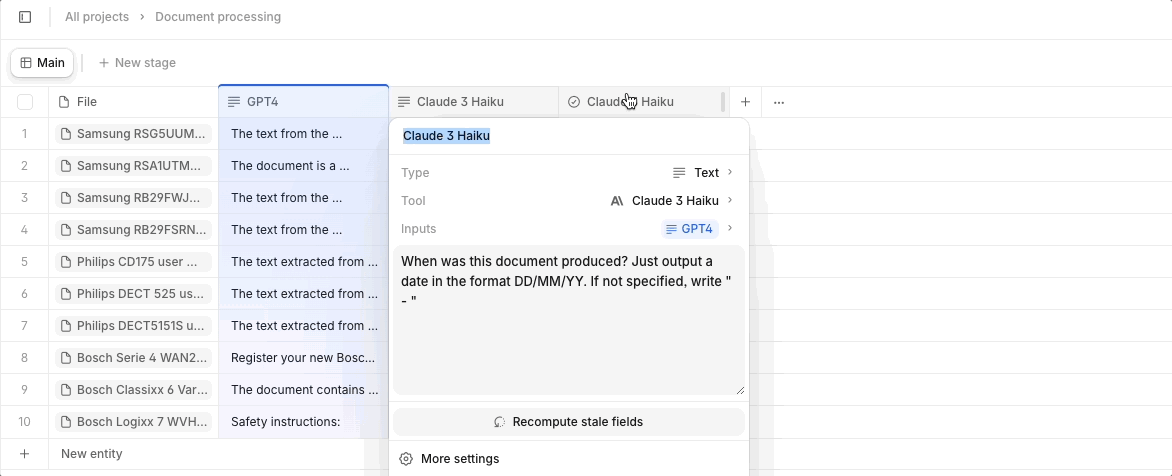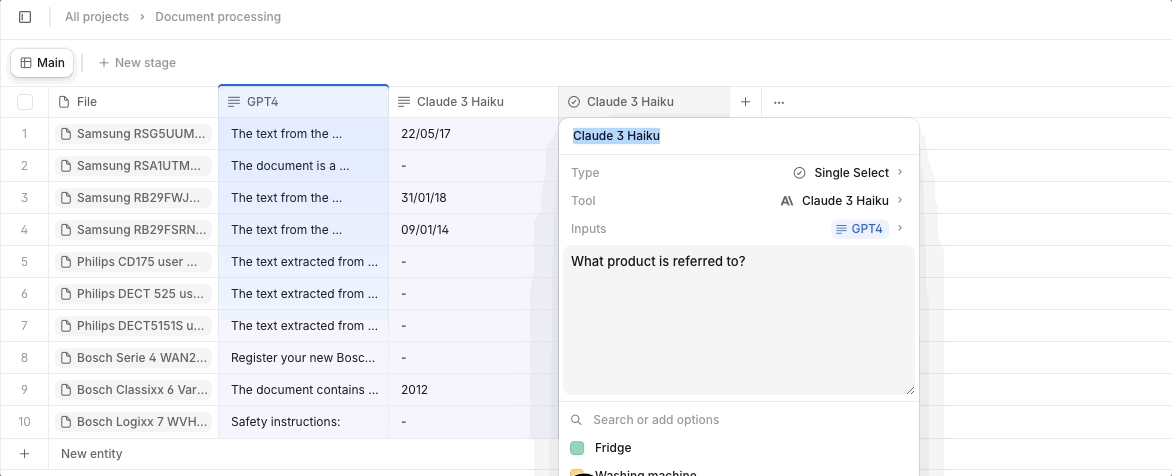
Every time you create a new property (column) with a source file as input - for instance, a large PDF document - the entire file's token content is consumed repeatedly. In the case of a 50-page financial report or 20-page legal contract, this becomes needlessly expensive very quickly. Instead, we recommend you extract all required information into one property using a single computation with a powerful model. You can then use smaller models that are a fraction of the cost, like Claude’s Haiku, for the simpler task of formatting the data into the desired output. This reduces the need for repetitive processing and helps you maintain a more streamlined, cost-effective workflow.
With this small change, one company using Go to process research papers saw radical improvements in token efficiency, going from processing 5 papers for $15 to processing 250 papers with just $20 (that is, $3 per paper to 8 cents!). We would expect similar improvements across any other document processing use case.
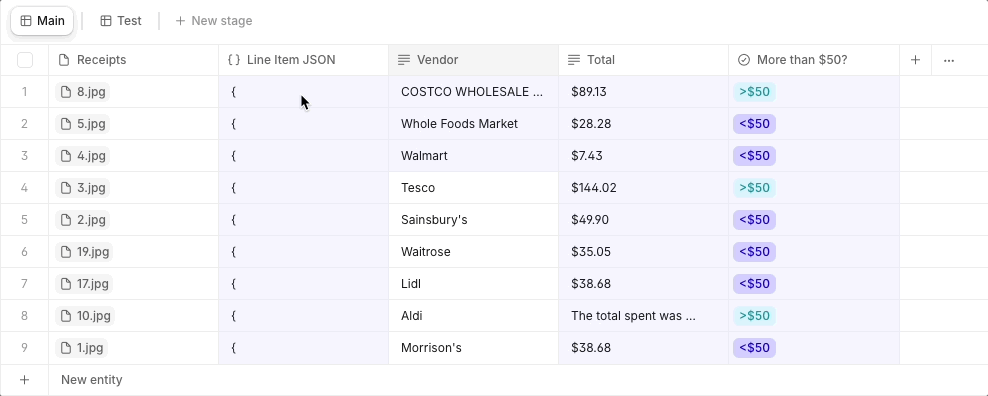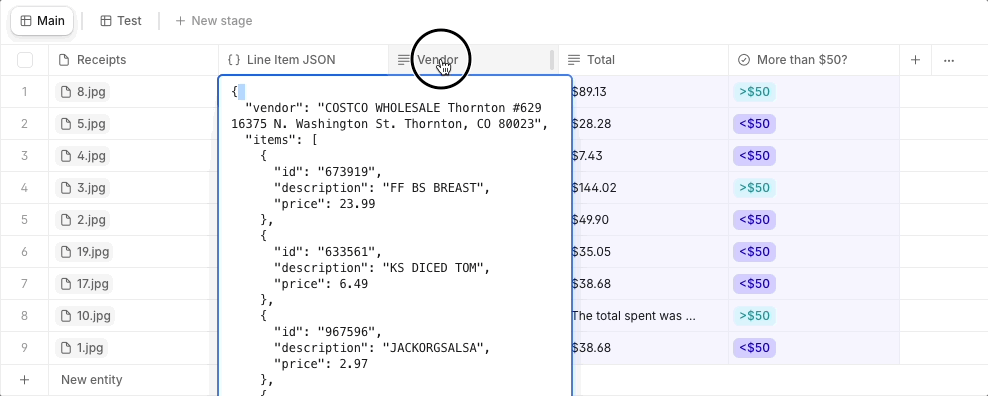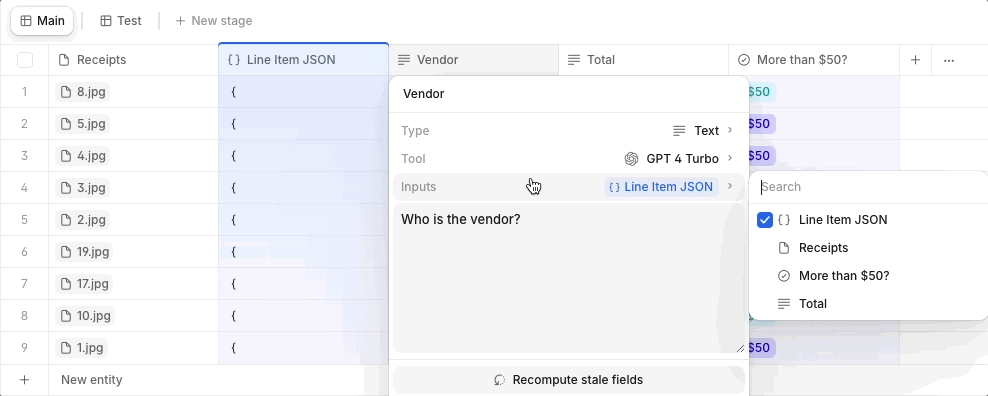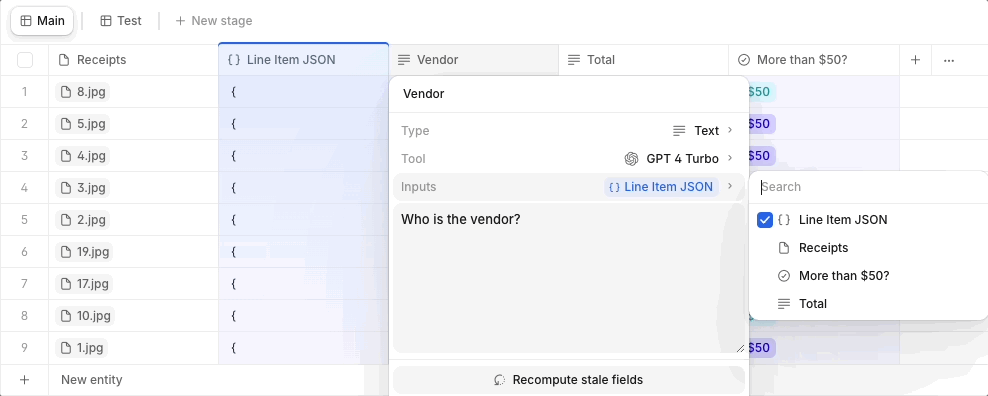
Tip 2: Use JSON as a Structured Input
Instead of feeding an expensive model directly with a large source document or file for every property, we’d recommend using JSON to structure relevant data fields first. You can then point cheaper models to this organized JSON input instead of processing the entire document or file. This setup helps minimize unnecessary token usage by limiting the information that models have to process.
For non-technical users, JSON is a common data format - think of it as a neat digital table or form where specific details are organized under clear labels. By using this method, we focus on processing only the necessary bits of information, like reading a summary instead of an entire book, which helps save time and resources when working with data models.
Tip 3: Choose the right model for your workflow
(Spoiler alert, we’re working on helping you with this)
Select models that match the granularity of your task, and keep in mind that some models are 100x more expensive than others. Larger models like Claude Opus or GPT4 Turbo are suitable for ambiguous or complex tasks requiring complex reasoning. However, for simpler properties or repetitive tasks, smaller, less expensive models can often provide similar results with a fraction of the token costs. Take a look at our AI Tools page for comparison of different LLMs!
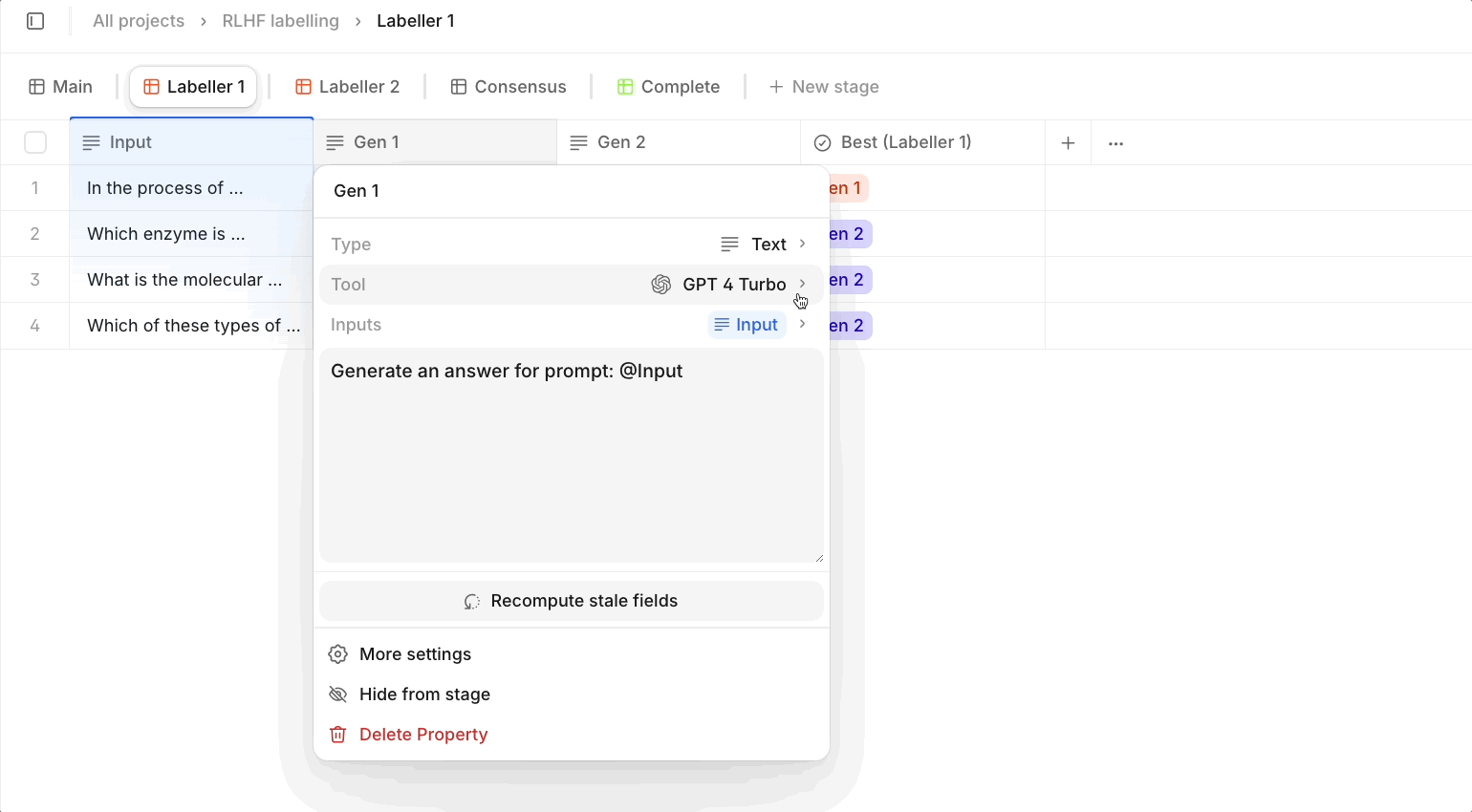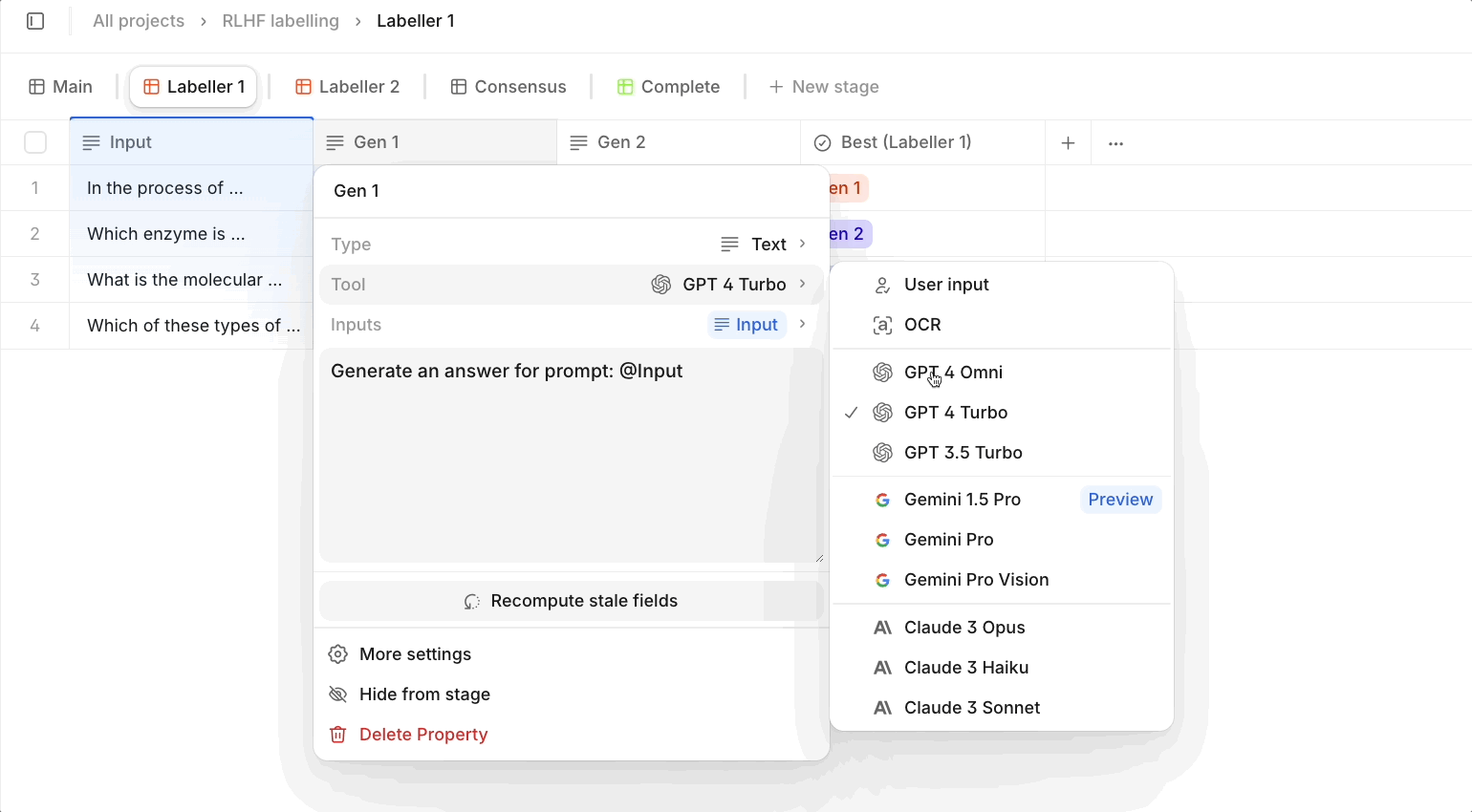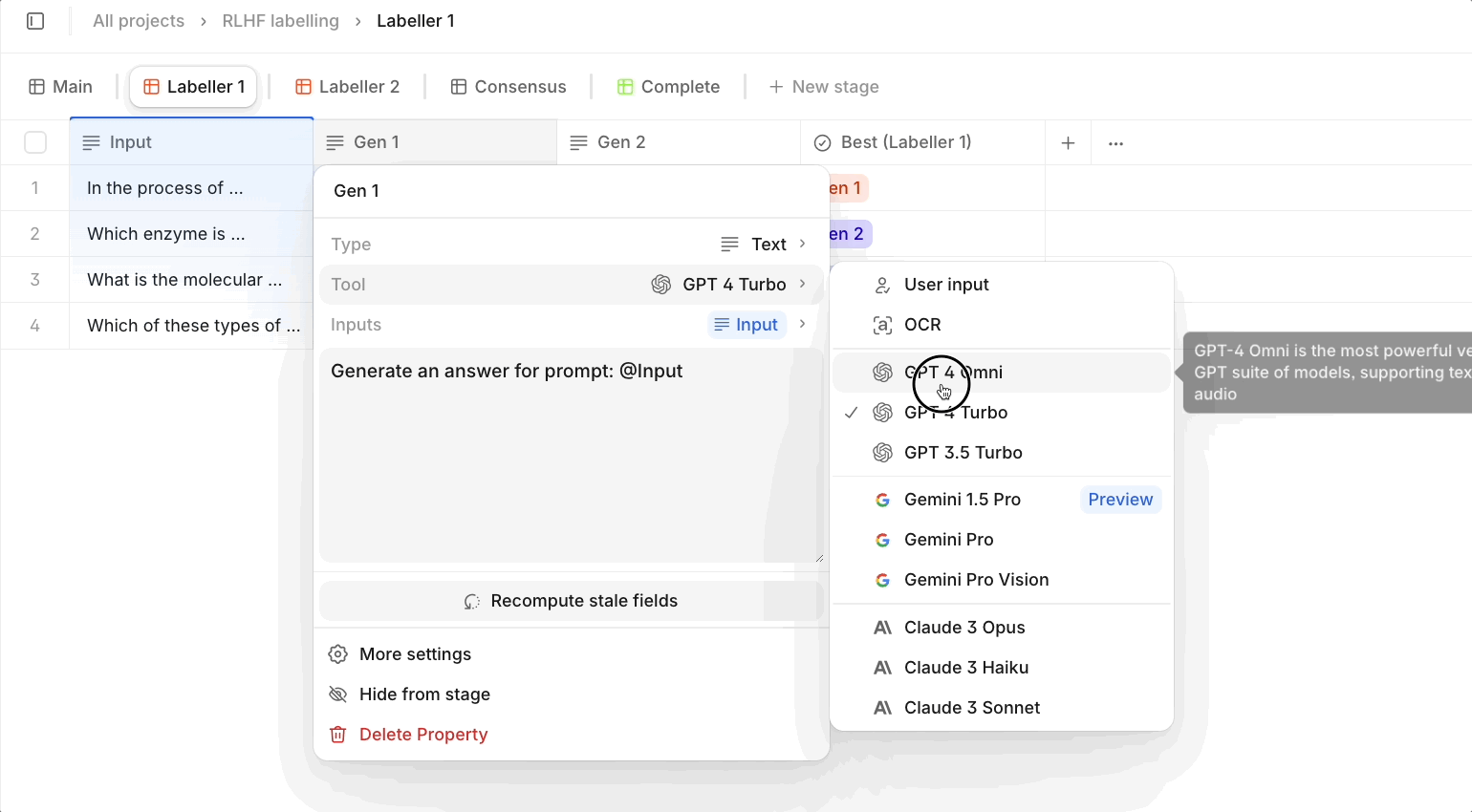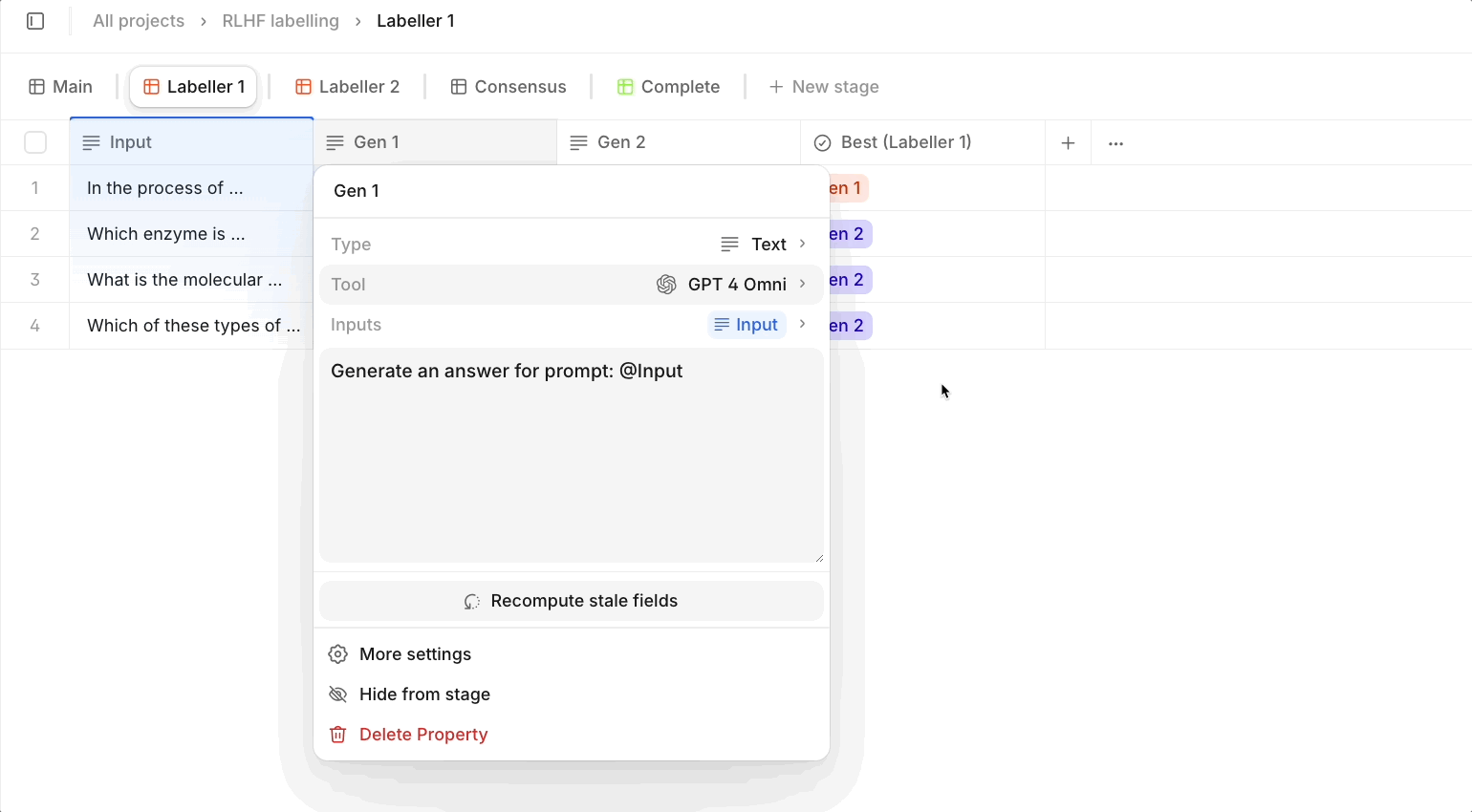
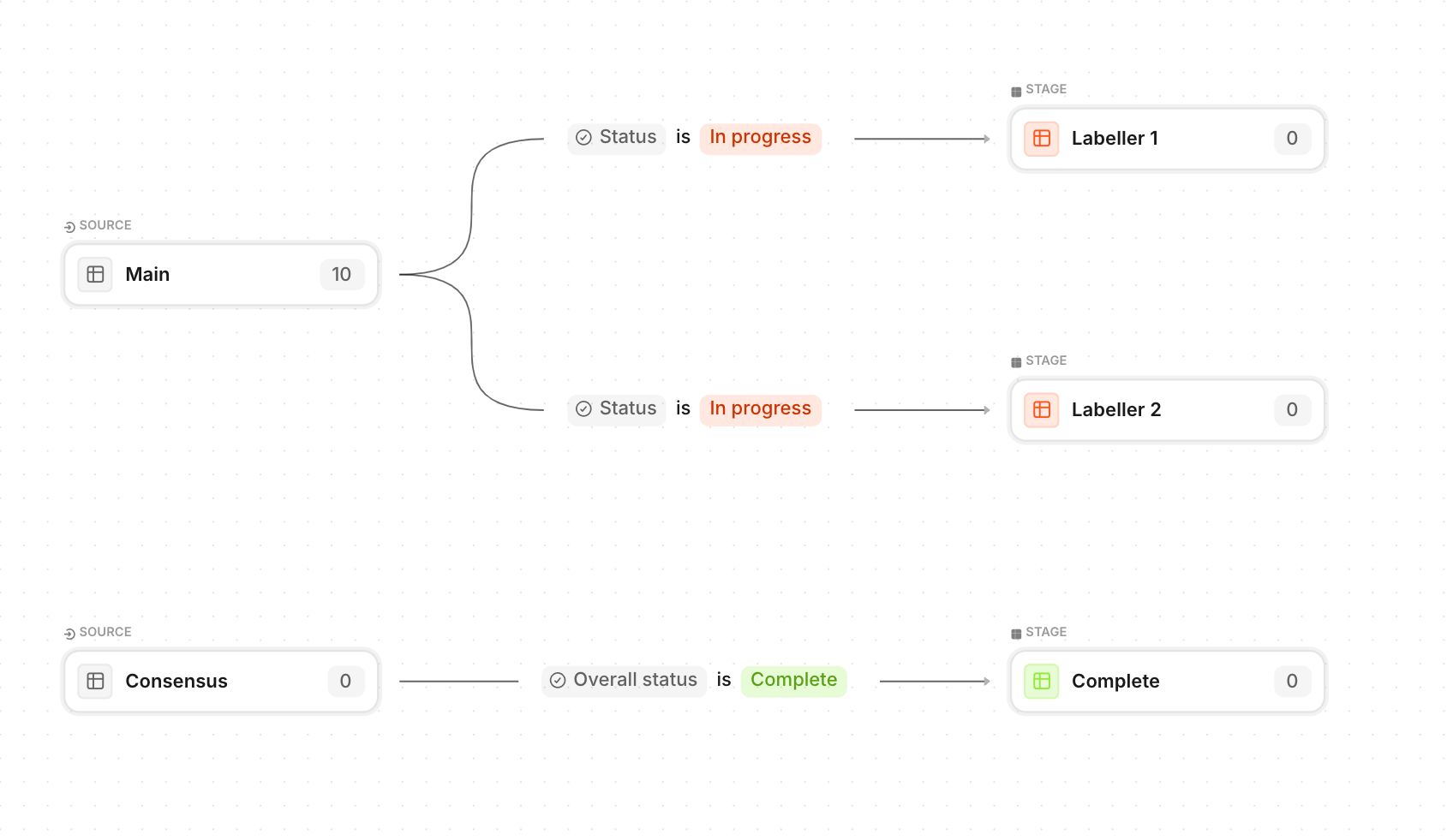
Tip 4: Use our Workflow feature and branching logic
Configure your data into different stages and workflows in order to route your data to different models, and make sure that you’re only running LLMs on the most relevant data at any given point. Here’s a video walkthrough of how to set up workflows for more information.
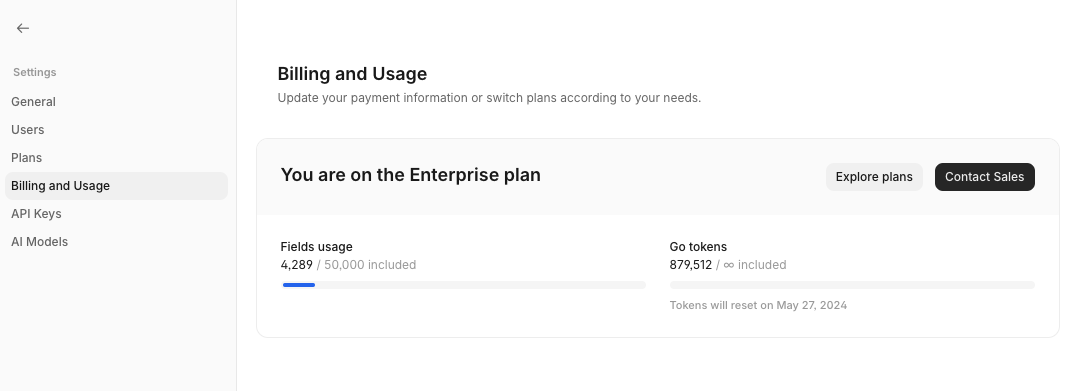
Tip 5: Monitor Token Usage Regularly
Set up monitoring to keep track of your model's token usage. You can monitor these in the Settings and Plans section of Go. Regularly reviewing can help identify patterns and opportunities to optimize.
By following these principles, you can leverage the full potential of V7 Go while optimizing your token usage and spend!
Updated 15 days ago